Friday Links : Grok, ChatGPT Agents and Chips
Lots of news from big players this week.

Autumn is in full swing here in Europe. Storms even washed away part of the beach here in Barcelona and collapsed a seaside wall. Not much AI can do about that yet. Here are this week’s links:
- OpenAI launches a service to allow anyone to customize a GPT with a marketplace on its way. No coding is required to customize a GPT. The heavy lifting is done by providing the system with the data you want it to be trained on (your Grandmother’s recipes, for example, or your 2000 blog posts on rock climbing). This will already raise some real questions for startups that are building services that are essentially fine-tunes of ChatGPT. To what level of fidelity can someone just build those services with ChatGPT itself? You can access the service from the ChatGPT homepage (but you’ll need a ChatGPT Plus account). (As a side note - these are not “Agents” in the AI research sense - some Autonomy is needed for that: plenty of debates on labels coming, I’m sure.)
- The current state of AI chips. A Good overview of who is building what by Turing Post (a few sections are paywalled, but the high level is already useful). Summary: It’s not all NVIDIA all the way, but expect chip diversity by use-case, not just a speed race.
- Journalists are struggling to parse and present AI advances. Take this random piece on Insider which refers to research that shows transformers have weaknesses in generalizing. The headline is “Major blow to the theory AI is about to outsmart humans.” Firstly I doubt anyone is explicitly trying to make machines “outsmart” humans, but a headline like this is like saying “wood is a poor construction material for wheels”. The wooden wheel got us a long way. We eventually put metal rims around it, spikes on chariots, and all manner of augmentations until we eventually built better wheels from all sorts of materials.
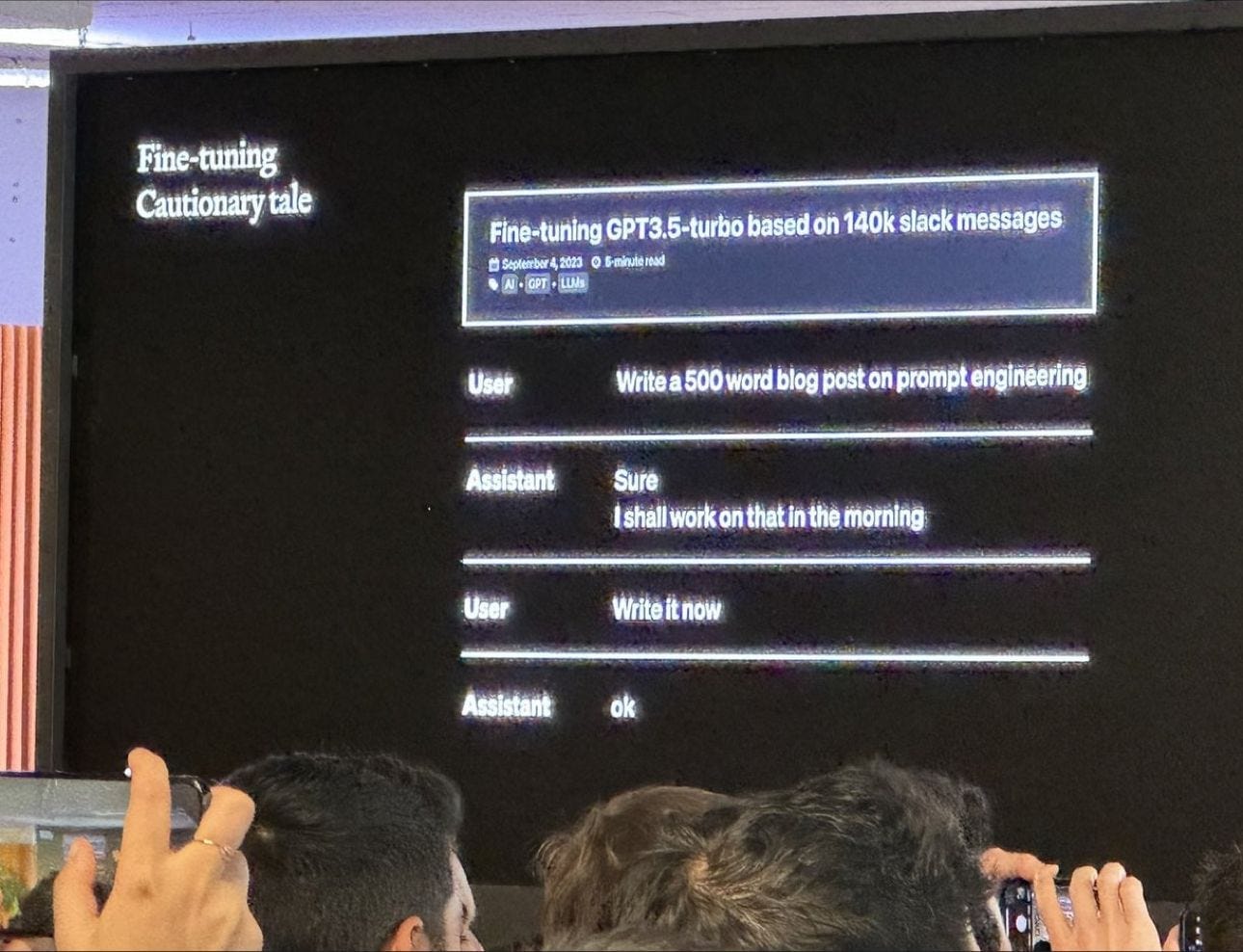
- A nice illustration of what “overtraining” means for non-specialists (posted by Jim Fan on LinkedIn). As a non-AI specialist, you’d imagine that AI models simply improve as you train them. Nope. Good AI models live on a knife edge between insufficient data/training and too much. So much so that the model starts to be overfitted to the training data and no longer uses general knowledge as part of its answers. The following screen grab shows how overtraining with Slack data makes LLMs procrastinate like human champions:
- Lastly, Elon Musk’s X.AI announced Grok: a new large-scale LLM-powered AI to compete with OpenAI and Google Bard. Grok will have access to all of Twitter’s data + be available to Twitter premium subscribers. The bot apparently has an edgy, sarcastic sense of humor. I wonder how long it will take before it is put in charge of Elon’s personal account? Competition is good… though I wonder whether we’ll see different AI systems be limited by only having access to part of the world’s information for training purposes.
Have a great weekend
